Tutorial
This tutorial will walk through Morphling Tuning (Morphling) concepts. You can also check the [video demo]({{< ref "tuning/tutorial/video" >}}).
Install Morphling
Follow the instructions to install Morphling. Go →
Run a tuning experiment
This example tunes a mobilenet model using grid search. The tunable configurations include resource/cpu, resource/memory, and runtime/batch_size.
From project root, run:
kubectl apply -f examples/experiment/experiment-mobilenet-grid.yaml
Explanation on the YAML
apiVersion: "morphling.kubedl.io/v1alpha1"
kind: ProfilingExperiment
metadata:
namespace: morphling-system
name: mobilenet-experiment-grid-1
spec:
objective:
type: maximize
objectiveMetricName: qps
algorithm:
algorithmName: grid
parallelism: 1
maxNumTrials: 18
clientTemplate:
spec:
template:
spec:
containers:
- name: pi
image: kubedl/morphling-http-client:demo
env:
- name: TF_CPP_MIN_LOG_LEVEL
value: "3"
- name: MODEL_NAME
value: "mobilenet"
resources:
requests:
cpu: 800m
memory: "1800Mi"
limits:
cpu: 800m
memory: "1800Mi"
command: [ "python3" ]
args: ["morphling_client.py", "--model", "mobilenet", "--printLog", "True", "--num_tests", "10"]
imagePullPolicy: IfNotPresent
restartPolicy: Never
backoffLimit: 1
servicePodTemplate:
template:
spec:
containers:
- name: resnet-container
image: kubedl/morphling-tf-model:demo-cv
imagePullPolicy: IfNotPresent
env:
- name: MODEL_NAME
value: "mobilenet"
resources:
requests:
cpu: 1
memory: "1800Mi"
limits:
cpu: 1
memory: "1800Mi"
ports:
- containerPort: 8500
tunableParameters:
- category: "resource"
parameters:
- parameterType: discrete
name: "cpu"
feasibleSpace:
list:
- "2000m"
- parameterType: discrete
name: "memory"
feasibleSpace:
list:
- "200Mi"
- "2000Mi"
- category: "env"
parameters:
- parameterType: discrete
name: "BATCH_SIZE"
feasibleSpace:
list:
- "1"
- "2"
Notes:
servicePodTemplatefield defines the model serving pod template, where the model is stored in the docker image. In this demo, we use tensorflow-serving as the serving backends.clientTemplatefield defines the stress-testing k8s job, which sends concurrent model serving requests to the serving pod, monitoring the response time, and eventually measures the maximum request concurrency this model can serve under a specific configuration. Morphling provides out-of-the-box stress-testing docker image for HTTP request. Check the documentation for more details
Inspect the tuning experiment
After the tuning experiment succeeded, run kubectl get pe:
NAME STATE AGE OBJECT NAME OPTIMAL OBJECT VALUE OPTIMAL PARAMETERS
mobilenet-experiment-grid-1 Succeeded 20h qps 32 [map[category:env name:BATCH_SIZE value:2] map[category:resource name:cpu value:2000m] map[category:resource name:memory value:2000Mi]]
Here, an optimal configuration is searched.
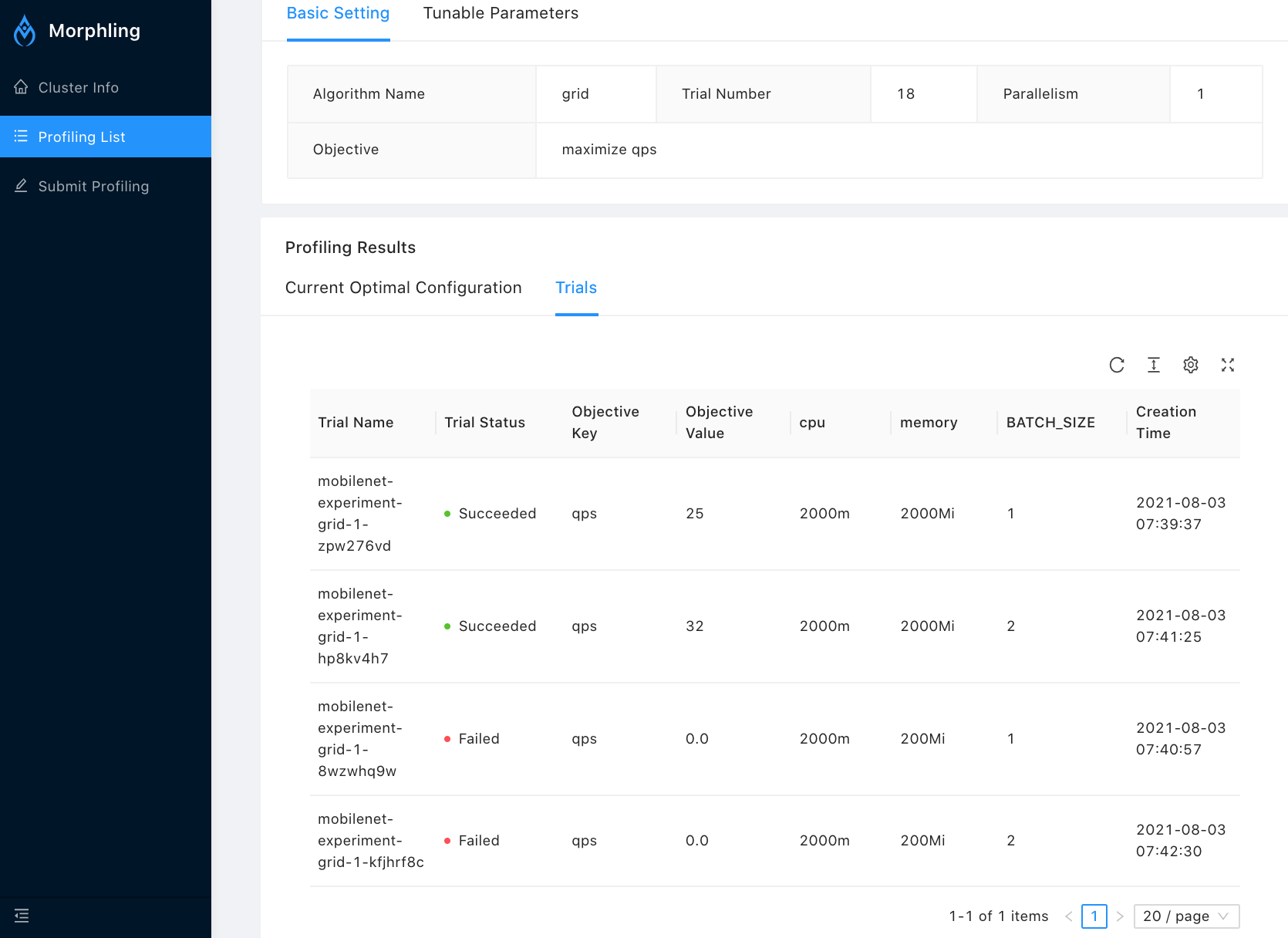
Inspect the tuning trials
Inspect the trials tested during the tuning experiment
$ kubectl get trial
NAME STATE AGE OBJECT NAME OBJECT VALUE PARAMETERS
mobilenet-experiment-grid-1-c588pqnx Failed 20h qps 0.0 [map[category:env name:BATCH_SIZE value:2] map[category:resource name:cpu value:2000m] map[category:resource name:memory value:200Mi]]
mobilenet-experiment-grid-1-f45hb5gp Succeeded 20h qps 26 [map[category:env name:BATCH_SIZE value:1] map[category:resource name:cpu value:2000m] map[category:resource name:memory value:2000Mi]]
mobilenet-experiment-grid-1-q9s8qwhr Failed 20h qps 0.0 [map[category:env name:BATCH_SIZE value:1] map[category:resource name:cpu value:2000m] map[category:resource name:memory value:200Mi]]
mobilenet-experiment-grid-1-sqzv8v26 Succeeded 20h qps 32 [map[category:env name:BATCH_SIZE value:2] map[category:resource name:cpu value:2000m] map[category:resource name:memory value:2000Mi]]
You can also monitor the tuning process, and obtain the tuning results from Morphling UI: