Design
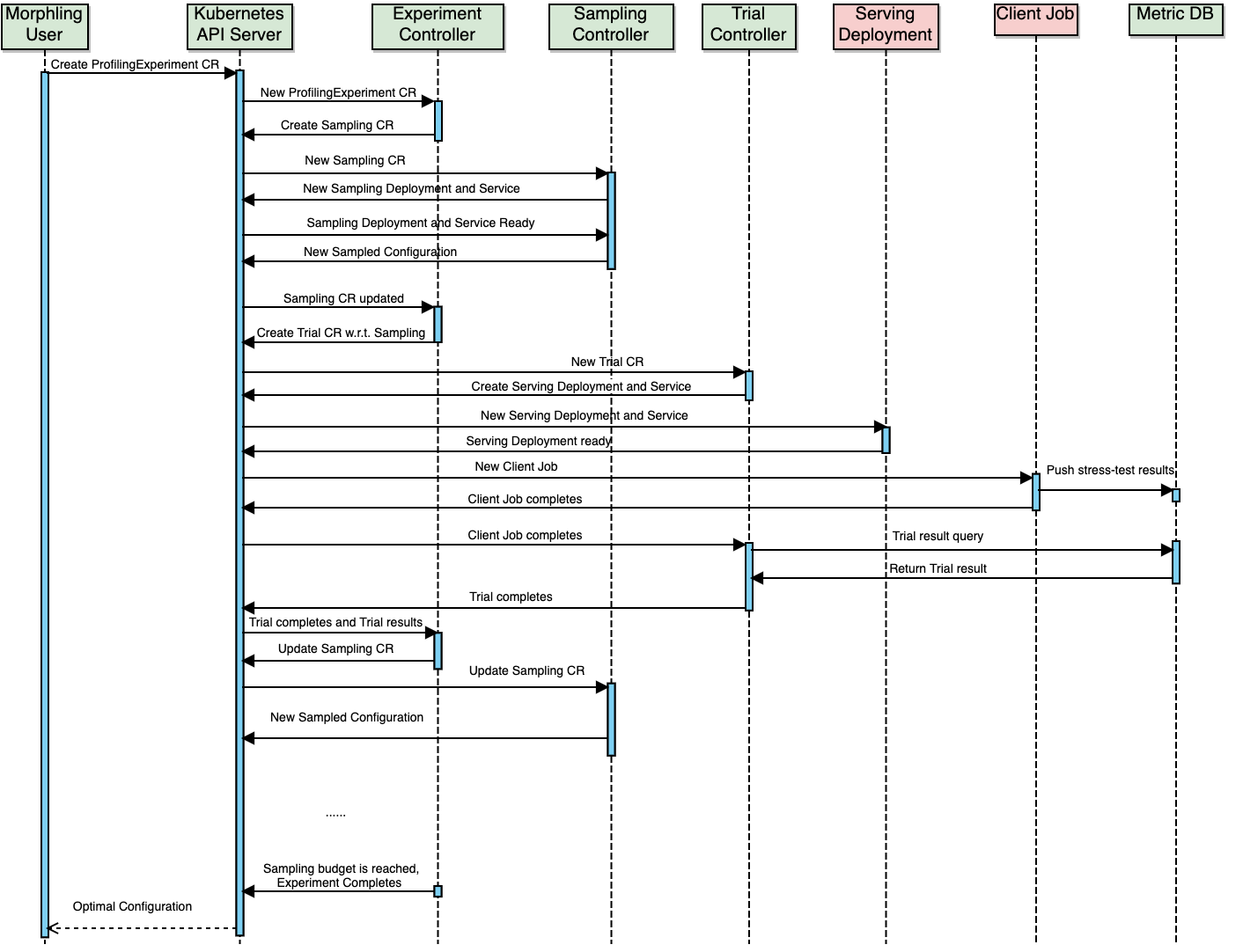
This diagram illustrates the workflow of a ProflingExperiment.
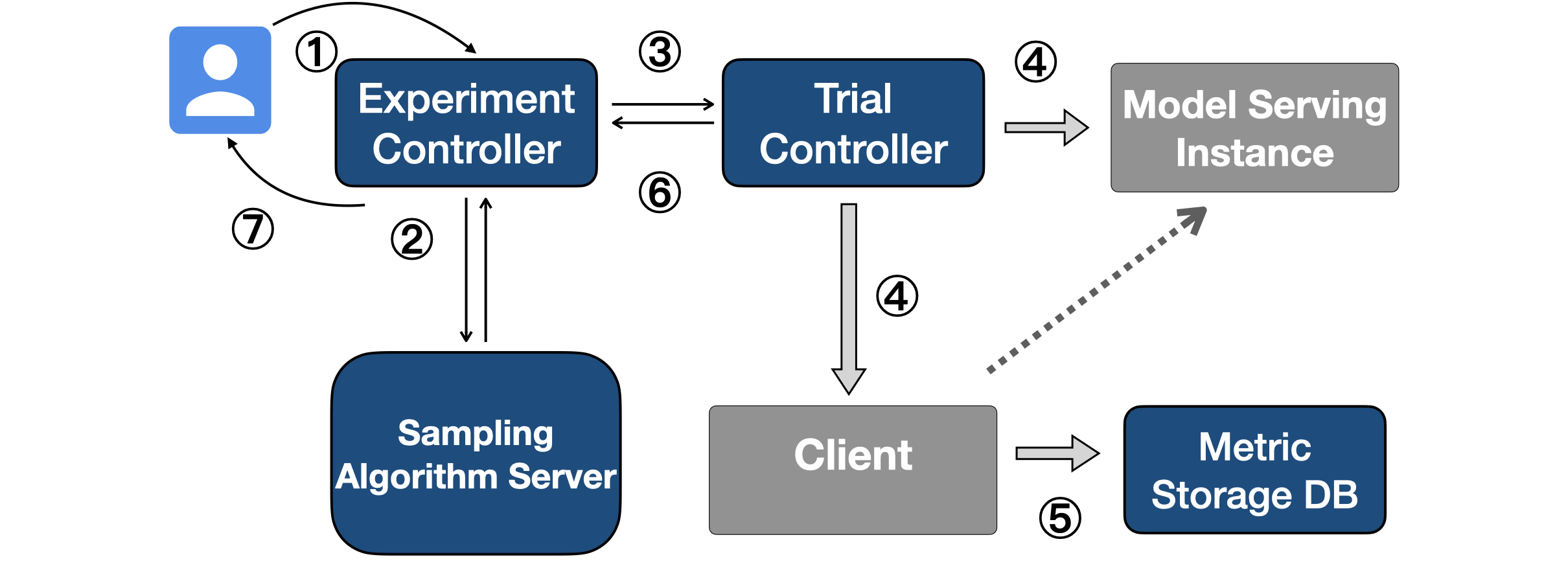
A user submits a
ProflingExperimentvia a RPC or front-end UI interface, specifying the ML model, tunable configuration parameters, optimization objectives, and sampling budgets.Within the sampling budget, Morphling iteratively communicates with the algorithm server to get the next configuration for sampling.
Then Morphling starts a
Trialto evaluate that sampling.For each
Trial, a model serving inference instanceDeploymentis launched, and its “readiness” is reported to trigger a client-side RPS stress-testJob.After the client
Jobcompletes, the measured peak RPS is stored in theDB.A
Trialfinishes, and the result is sent to theProflingExperiment.The
ProflingExperimentcompletes when the sampling budget is reached.
The sequence diagram of the ProflingExperiment workfolow is shown as follows: